생산관리시스템(MES)을 도입한 기업의 전산실이나 서버실을 들여다보면 흥미로운 현상을 발견할 수 있습니다. 매일 생산 라인에서 쏟아지는 수만 건의 데이터가 서버의 하드디스크를 가득 채우고 있습니다. 클라우드를 사용한다면 매월 청구되는 스토리지 유지 비용이 만만치 않습니다.
그런데 정작 품질 회의 시간이 되면, 실무자들은 시스템 화면을 캡처하거나 텍스트 파일로 데이터를 일일이 내려받아 다시 자신만의 엑셀 시트에 복사하고 붙여넣는 막노동을 반복합니다. 경영진이 “지난달 대비 B라인의 불량률 추이를 새로운 관점에서 보고해달라”고 지시라도 하는 날에는, 시스템 개발업체에 전화를 걸어 수백만 원의 추가 화면 개발 견적서를 받아들고 한숨을 쉬게 됩니다.
수천만 원, 수억 원을 들여 데이터를 모았는데 왜 우리는 여전히 엑셀 수작업에서 벗어나지 못하고, 새로운 보고서 하나를 볼 때마다 시스템 업체에 끌려다녀야 할까요?
오늘은 제조업계의 데이터 활용에 깊게 뿌리내린 고정관념들을 밑바닥부터 해체하고, 껍데기뿐인 보고서 화면 개발을 멈추는 대신 ‘실무자가 직접 데이터를 요리할 수 있는’ 본질적인 시스템 아키텍처 설계에 대해 이야기해 보겠습니다.
1. 데이터 활용을 가로막는 3가지 치명적인 착각
비용 누수를 막고 데이터의 진짜 가치를 뽑아내려면, 우리가 시스템 설계 시 당연하다고 믿어온 전제 조건들이 정말 물리적인 한계 때문인지, 아니면 단순히 과거의 비효율적인 습관을 답습하는 것인지 명확히 구분해야 합니다.
착각 A: “모든 분석 보고서 화면은 MES 프로그램 안에 개발되어 있어야 한다”
- 실체 파악: 시스템을 구축할 때 가장 흔히 범하는 오류는 현장에서 발생할 수 있는 모든 경우의 수(일보, 월보, 불량률 통계, 수율 분석 등)를 미리 예측하여 시스템 내부에 고정된 화면으로 만들어두려 한다는 점입니다.
- 진단: 이는 불가능한 목표입니다. 비즈니스 환경과 경영진의 관심사는 매일 변합니다. 어제는 온도에 따른 불량률이 중요했지만, 오늘은 원자재 로트(Lot)별 수율이 궁금할 수 있습니다. 이 모든 변수를 프로그램 소스코드에 하드코딩하여 가둬두는 것은, 물리적으로 불가능한 유연성을 억지로 흉내 내는 것에 불과합니다. 결국 쓰지 않는 수백 개의 메뉴만 덩그러니 남게 됩니다.
착각 B: “데이터베이스(DB)에서 정보를 꺼내려면 무조건 개발자의 복잡한 쿼리가 필요하다”
- 실체 파악: 데이터가 저장된 서버는 위험하고 복잡한 곳이니, 오직 IT 전문가나 외주 개발업체만이 접근해서 결과물만 예쁘게 포장해 실무자에게 전달해야 한다고 굳게 믿습니다.
- 진단: 과거에는 사실이었을지 모르나, 지금은 다릅니다. 시스템 구조를 설계할 때 데이터 저장소(원천 데이터)와 데이터 소비소(분석 뷰)를 분리하는 아키텍처를 취하면 됩니다. 복잡한 원시 데이터를 실무자가 이해하기 쉬운 형태의 ‘가상의 표(View)’로 묶어두는 뼈대 작업만 초기에 해두면, 이후에는 굳이 개발자가 개입할 이유가 없습니다.
착각 C: “현장 품질 담당자나 생산 실무자는 데이터를 다룰 줄 모른다”
- 실체 파악: 실무자들에게 데이터 분석 툴을 주어도 제대로 활용하지 못할 것이라는 막연한 두려움입니다.
- 진단: 현업에 종사하는 실무자들은 이미 엑셀 피벗 테이블과 VLOOKUP의 달인들입니다. 그들이 데이터를 다루지 못하는 것이 아니라, 데이터를 안전하고 쉽게 가져올 ‘파이프라인’을 제공받지 못했을 뿐입니다.
이러한 착각에서 벗어나, 우리 공장의 데이터 활용 구조를 근본적으로 진단하고 싶으시다면 전문가의 조언을 받아보시기 바랍니다. 👉 엠이에스코리아 데이터 활용 및 시스템 구조 무상 진단받기
2. 껍데기를 버리고 본질만 남긴 아키텍처: 데이터 독립 선언
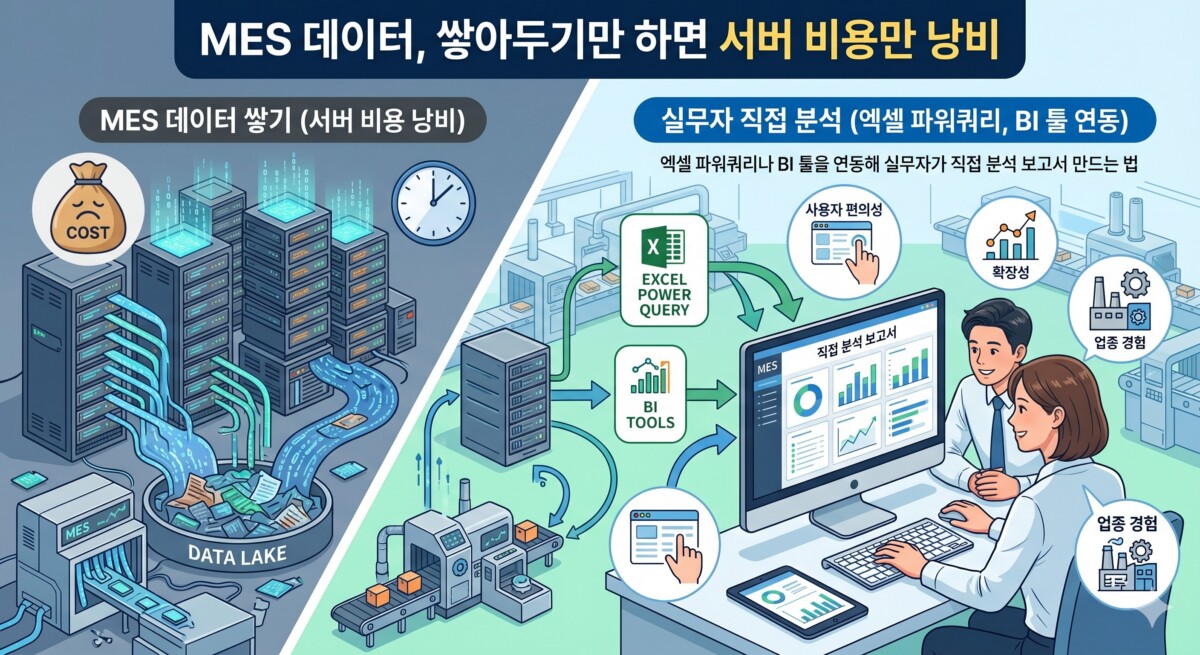
문제를 해결하기 위해서는 구조를 완전히 뒤집어야 합니다. ‘데이터 수집’과 ‘데이터 분석’을 하나의 무거운 프로그램 안에 욱여넣는 방식을 폐기하고, 오직 각각의 본질적인 역할에만 집중하도록 시스템을 두 동강 내는 것입니다.
첫째, MES의 역할 축소와 본질 집중 (Input)
MES는 철저하게 데이터를 ‘빠르고, 정확하게, 무결성을 유지하며 수집’하는 역할에만 집중해야 합니다. 사출, 가공, 조립, 금형, 식품 등 업종을 불문하고 현장에서 발생하는 기계의 상태 값과 작업자의 조작 이력을 흔들림 없이 데이터베이스(PostgreSQL, MSSQL 등)에 차곡차곡 적재하는 최전방 수비수 역할만 수행하도록 설계합니다. 화려한 차트를 그리는 무거운 로직은 과감히 걷어냅니다.
둘째, 실무자 친화적 데이터 마트(Data Mart) 설계 (Middleware)
수집된 날것의 데이터(Raw Data)는 매우 복잡합니다. 이를 실무자가 즉시 이해할 수 있도록 초기에 안전한 ‘데이터 뷰(View)’를 깎아두는 것이 핵심입니다. 예를 들어 ‘Table_A’와 ‘Table_B’를 조인하여, 실무자의 눈에는 그저 [생산일자], [품목명], [작업자], [불량수량]이라는 아주 직관적인 열(Column)로만 보이도록 중간 지대를 설계합니다. 이 공간은 데이터를 읽기만 할 수 있으므로, 실무자가 아무리 데이터를 분석해도 원본 시스템이 멈추거나 훼손될 위험이 물리적으로 완벽히 차단됩니다.
셋째, 범용 분석 도구의 직접 호출 (Output)
이제 시스템 내부에 비싼 돈을 주고 통계 화면을 만들 필요가 없습니다. 실무자들의 PC에 이미 깔려 있는 엑셀(Excel)의 ‘파워쿼리(Power Query)’ 기능이나, Power BI, Tableau 같은 무료 또는 저비용의 시각화 도구를 방금 만든 데이터 마트에 직접 파이프라인으로 연결합니다. 사용자가 엑셀에서 ‘새로고침’ 버튼을 누르는 순간, 서버에 쌓여 있던 최신 생산 데이터가 엑셀 표 안으로 즉각 쏟아져 들어옵니다.
3. 실무자가 주도하는 데이터 분석이 가져오는 극적인 변화
이러한 뼈대 설계가 완성되면, 현장에는 마법 같은 변화가 일어납니다.
- 무한한 분석의 자유: 품질 담당자는 엑셀로 불러온 데이터를 바탕으로 마우스 드래그 몇 번이면 피벗 차트를 완성합니다. 경영진이 “작업자별, 시간대별 불량률 교차 분석”을 요구해도, 개발사에 전화할 필요 없이 5분 만에 엑셀 시트에서 조합하여 보고서를 제출합니다.
- 유지보수 비용 제로화: 새로운 분석 지표가 필요할 때마다 발생하던 UI 커스터마이징 비용이 완전히 사라집니다. 화면은 엑셀과 BI 툴이 대신하므로, 기업은 데이터 수집의 정합성에만 예산을 집중할 수 있습니다.
- 어떤 업종이든 적용 가능한 유연성: 이 구조는 금속 가공 공장의 절삭유 온도 분석이든, 식품 공장의 살균 시간 추적이든 데이터의 이름표만 다를 뿐 완벽하게 동일한 논리로 작동합니다. 특정 산업군에 얽매이지 않는 가장 진보된 데이터 확장 방식입니다.
4. 엠이에스코리아: 데이터의 진짜 주인을 찾아주는 시스템 설계
수많은 개발사가 화면을 하나라도 더 만들어 수익을 올리려 할 때, 진정한 전문가는 고객이 스스로 데이터를 통제할 수 있는 튼튼한 인프라를 지어주는 데 집중합니다.
엠이에스코리아(MES Korea)는 30년에 걸친 깊이 있는 산업 소프트웨어 설계 노하우를 바탕으로, 데이터를 시스템에 가두지 않고 실무자의 손에 쥐여주는 가장 합리적인 아키텍처를 제공합니다.
단순히 화면에 데이터를 뿌려주는 1차원적인 솔루션이 아닙니다. 내부 데이터베이스 구조를 철저히 모듈화하고, 최신 데이터 플랫폼(BI, 엑셀 파워쿼리 등)과의 즉각적인 파이프라인 개설이 가능하도록 데이터 뷰를 표준화하여 설계합니다.
불필요한 보고서 화면 개발 거품을 완전히 걷어냈기에, 중소·중견 제조기업들도 저렴한 초기 도입비만으로도 대기업 수준의 데이터 인프라를 구축할 수 있습니다. 이후의 분석과 보고서 확장은 온전히 귀사 실무자들의 엑셀 활용 능력만으로 무한히 뻗어나갈 수 있습니다.
서버실에서 먼지만 쌓여가며 비용만 낭비하는 데이터, 이제는 공장의 수율을 높이고 비즈니스를 성장시키는 날카로운 무기로 바꿔야 할 때입니다. 데이터 분석의 완벽한 독립, 그 첫 단추를 엠이에스코리아의 견고한 아키텍처 설계와 함께 시작하십시오.